经常用 Claude Code 或 Codex 写项目的人应该都有这个感觉:上下文一长,token 哗哗地烧。搜一下 100 个文件,光搜索结果就 17000 多 token;调试一个 SRE 问题,日志输出直接干到 65000 token。
钱是一方面,更烦的是上下文窗口被工具输出塞满之后,模型真正能拿来思考的空间反而变小了。你花大价钱买的推理能力,有一半浪费在“读废话”上。
最近发现一个工具叫 Headroom,专门干这件事——在上下文送到模型之前,先帮你压缩一遍。实测压缩率在 60%–95%,而且压缩是可逆的,模型随时能把原始数据要回来。
最关键的是:它对 Claude Code 和 Codex 的支持是一行命令搞定的。
Headroom 是什么
简单说:它是一个跑在本地的上下文压缩层,插在你的 Agent 和 LLM 之间。所有 Agent 读到的东西——工具输出、日志、RAG 检索结果、文件内容、对话历史——在送到模型之前,先经过 Headroom 压缩。
压缩完的 token 少了,但答案质量基本不变。官方基准测试跑过 GSM8K(数学)、TruthfulQA(事实)、SQuAD v2(问答)、BFCL(工具调用),压缩后的准确率和原始上下文持平,有些甚至略有提升。
它有三种接入方式:
headroom wrap——一行命令包裹你的 Agent,最省事headroom proxy——启动一个本地代理,改个环境变量就行compress()——直接当 Python/TypeScript 库调用,适合开发者
对于 Claude Code 和 Codex 用户,headroom wrap 是最直接的路径。
安装
一行命令,Python 3.10 以上:
pip install "headroom-ai[all]"如果你只想要核心功能,不装可选依赖:
pip install headroom-aiNode.js 用户:
npm install headroom-aiDocker 也行:
docker pull ghcr.io/chopratejas/headroom:latest装完验证一下:
headroom --version看到版本号就说明没问题。
Claude Code 接入
这是最简单的部分。一行命令:
headroom wrap claude它会自动启动本地压缩代理,然后把 Claude Code 的请求全部路由过去。你正常使用 Claude Code,完全无感——但每一个发出去的上下文都被压缩过了。
想看省了多少:
headroom perf会告诉你总共压缩了多少 token、压缩率是多少。
如果你不想用 wrap,也可以手动走代理模式:
# 终端 1:启动代理
headroom proxy --port 8787
# 终端 2:让 Claude Code 走代理
ANTHROPIC_BASE_URL=http://localhost:8787 claude效果一样,只是需要你自己管理代理进程。
进阶选项:
Claude Code 的 wrap 支持两个额外参数:
--memory——开启跨会话持久记忆,Claude Code 下次打开还记得上次的上下文--code-graph——开启代码图谱分析,压缩代码时更智能
headroom wrap claude -- --memory --code-graphCodex 接入
Codex 同样一行命令:
headroom wrap codex跟 Claude Code 的体验完全一样——代理自动启动,Codex 的请求全部经过压缩。而且 Codex 和 Claude Code 可以共享记忆,也就是说你在 Claude Code 里积累的项目上下文,Codex 也能用。
代理模式也适用:
headroom proxy --port 8787
OPENAI_BASE_URL=http://localhost:8787/v1 codex压缩效果到底怎么样
官方给了一组真实工作负载的数据:
| 工作负载 | 压缩前 | 压缩后 | 省了多少 |
|---|---|---|---|
| 代码搜索(100 条结果) | 17,765 | 1,408 | 92% |
| SRE 事故调试 | 65,694 | 5,118 | 92% |
| GitHub Issue 分类 | 54,174 | 14,761 | 73% |
| 代码库探索 | 78,502 | 41,254 | 47% |
代码搜索和日志调试的压缩率最高,因为这类内容里大量重复和冗余信息。代码探索低一些,但也能省将近一半。
对于用 Opus 级别模型的人来说,输出 token 的价格是输入的 5 倍。Headroom 还有一个输出压缩功能,可以减少模型回复时的废话:
export HEADROOM_OUTPUT_SHAPER=1
headroom proxy --port 8787它会在系统提示末尾追加一句“简洁回复,不要重复上下文”,同时对简单操作(比如读文件后的回复)降低模型的推理深度。实测大概能再省 30% 的输出 token。
它怎么做到的
Headroom 内部有三个核心压缩器,根据内容类型自动路由:
- SmartCrusher——处理 JSON 数据。搜索结果、API 返回、数据库行这种大段 JSON,它会保留关键字段,丢弃冗余数组元素。典型压缩率 70%–90%。
- CodeCompressor——基于 tree-sitter 的 AST 感知压缩。保留 import、函数签名、类型定义,压缩函数体。支持 Python、JS、Go、Rust、Java、C++。典型压缩率 40%–70%。
- Kompress-base——一个在 HuggingFace 上开源的自研模型,专门训练来做文本和日志压缩。
最重要的一点:压缩是可逆的。Headroom 本地缓存了所有原始数据,模型如果需要某个被压缩掉的细节,可以通过 headroom_retrieve 工具把它要回来。不像有些工具压缩完就丢数据了,Headroom 是“压缩但不丢失”。
还有一个 CacheAligner,做的事情是稳定消息前缀,让 Anthropic 和 OpenAI 的 KV 缓存能真正命中。很多时候你以为开了缓存,实际上每次请求的前缀都在变,缓存根本没生效。CacheAligner 解决的就是这个问题。
几个实用命令
# 查看当前压缩统计
curl http://localhost:8787/stats
# 从失败会话中学习,自动写入 CLAUDE.md / AGENTS.md
headroom learn
# 自动检测你的口癖,调整输出简洁度
headroom learn --verbosity --apply
# 更新 Headroom
headroom updateheadroom learn 这个功能挺有意思——它会分析你过去失败的会话,找到问题在哪,然后把修正建议写进项目的 CLAUDE.md 或 AGENTS.md。相当于让 AI 从自己的错误里学东西。
一定要看
虽然安装命令很简单,但是安装过程也是让我折腾了不少时间,如果你确定要安装或者安装过程中也遇到了跟我一样的问题,那么能减少你不少时间。
如果你使用的 Windows 安装遇到了 error: Microsoft Visual C++ 14.0 or greater is required. 这个错误,是因为环境缺少了 MSVC Build Tools,通过以下命令安装后再尝试:
winget install --id Microsoft.VisualStudio.2022.BuildTools -e --override "--wait --quiet --add Microsoft.VisualStudio.Workload.VCTools --includeRecommended"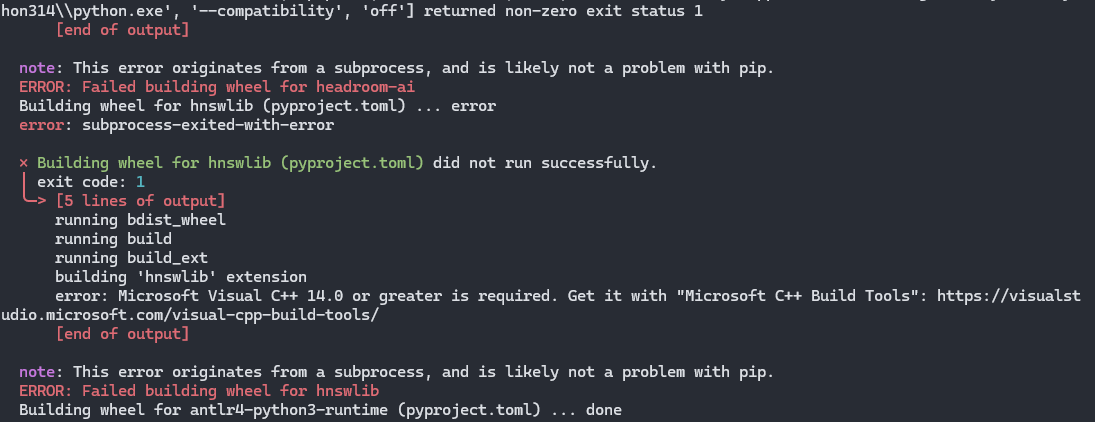
如果在安装过程中遇到 error: the configured Python interpreter version (3.14) is newer than PyO3's maximum supported version (3.13) 这个错误,PyO3 支持最高 Python 版本为 3.13 ,使用下方命令尝试:
# 推荐直接安装 Python 3.12
winget install --id Python.Python.3.12 -e
# 安装后重新打开新终端窗口:
py -3.12 -m venv .venv-headroom
.\.venv-headroom\Scripts\Activate.ps1
python -m pip install -U pip setuptools wheel
pip install "headroom-ai[all]"直至安装完成即可。
如果以上两个问题你都没有遇到,并且在安装使用过程中遇到了别的错误,不要着急,这时候就用 Claude Code 或者 Codex 来修复吧~
说句实话
token 压缩这个方向之前也见过几个工具,但大部分要么只压缩特定类型的内容,要么是托管服务需要把数据发出去。Headroom 好就好在它什么都压、本地跑、而且压缩完还能反悔。
一行 headroom wrap claude 就能跑起来,没有配置成本。如果你用 Claude Code 或 Codex 的频率比较高,建议试一下——跑完 headroom perf 看看自己省了多少,数字不会骗人。
项目地址:https://github.com/chopratejas/headroom